
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 낙관적락 비관적락 차이
- 디자인 패턴
- annotation
- JPA
- 캠프
- JPA 동시성
- Android
- 개발
- JPA Lock
- 스프링
- spring security
- spring
- 스프링 log
- 안드로이드
- spring security 인증
- Pessimistic Lock
- Inno DB
- Redis
- 스마일게이트
- 스프링 로그
- 서버
- 서버개발캠프
- bean
- 암호화
- component
- JPA 비관적락
- Transaction isolation level
- JPA 낙관적락
- flask
- Optimistic Lock
- Today
- Total
모르는게 많은 개발자
[Kafka] Kafka Connect 개념/예제 본문
이번 포스팅에서 Kafka의 Connector의 대해 포스팅하고자한다.
Kafka Connect란?
먼저 Kafka는 Producer와 Consumer를 통해 데이터 파이프라인을 만들 수 있다. 예를 들어 A서버의 DB에 저장한 데이터를 Kafka Producer/Consumer를 통해 B서버의 DB로도 보낼 수 있다. 이러한 파이프라인이 여러개면 매번 반복적으로 파이프라인을 구성해야줘야한다. KafkConnect는 이러한 반복적인 파이프라인 구성을 쉽고 간편하게 만들 수 있게 만들어진 Apache Kafka 프로젝트중 하나다.

위 사진을 보면 Kafka Connect를 이용해 왼쪽의 DB의 데이터를 Connect와 Source Connector를 사용해 Kafka Broker로 보내고 Connect와 Sink Connector를 사용해 Kafka에 담긴 데이터를 DB에 저장하는 것을 알 수 있다.
여기서 중요한 건 Connect와 Connector의 차이와 Source Connector와 Sink Connector이다.
Connect: Connector를 동작하게 하는 프로세서(서버)
Connector: Data Source(DB)의 데이터를 처리하는 소스가 들어있는 jar파일
Source Connector: data source에 담긴 데이터를 topic에 담는 역할(Producer)을 하는 connector
Sink Connector: topic에 담긴 데이터를 특정 data source로 보내는 역할(Consumer 역할)을 하는 connector
또한 Connect는 단일 모드(Standalone)와 분산 모드(Distributed)로 이루어져있다.
단일 모드(Standalone): 하나의 Connect만 사용하는 모드
분산 모드(Distributed): 여러개의 Connect를 한개의 클러스트로 묶어서 사용하는 모드.
-> 특정 Connect가 장애가 발생해도 나머지 Connect가 대신 처리하도록 함
Kafka Connect는 REST API를 사용해서 Connector를 등록 및 사용할 수 있다. 이제 예제를 한번 해보자.
Kafka Connect 예제
이번 예제에서 mysql table에 데이터를 insert하면 다른 table에 데이터가 그대로 저장되는 예제를 해본다.
먼저 선작업으로 DB에 Table을 하나 만들자.
CREATE SCHEMA test;
CREATE TABLE test.users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
)
Kafka 설치
다운로드 링크 : https://kafka.apache.org/downloads
설치후 해당 디렉토리 이동후 아래처럼 server.properties 파일을 열어
$ vi config/server.propertieslistneres=PLAINTEXT://:9092 주석을 풀고 localhost를 입력해준다.

kafka 디렉토리에서 아래의 명령어를 통해 zookeeper server와 kafka broker를 실행해준다.
$ ./bin/zookeeper-server-start.sh ./config/zookeeper.properties
$ ./bin/kafka-server-start.sh ./config/server.properties
Kafka Connect 설치
다운로드 링크: https://packages.confluent.io/archieve/6.1/confluent-community-6.1.0.tar.gz
설치후 kafka-connect 디렉토리에서 아래 명령어로 kafka-connect 실행(zookeeper와 kafka broker가 실행되어있어야함)
$ ./bin/connect-distributed ./etc/kafka/connect-distributed.properties실행하고 나서 kafka 디렉토리에서 아래 명령어를 실행하여 topic 리스트를 확인하면
$ ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list다음과 같은 topic이 생성된 걸 확인할 수 있다.

Connector 설치
JDBC Connector 다운로드 링크 : https://docs.confluent.io/5.5.1/connect/kafka-connect-jdbc/index.html
설치를 하면 아래의 디렉토리가 설치된다.

Kafka Connect 디렉토리에서
$ vi etc/kafka/connect-distributed.properties아래처럼 plugin.path={kafka connect jdbc plugin 경로}/lib을 입력해준다.

Mysql Connector 설치
connector에서 mysql을 사용하기 위해 추가적으로 mysql connector를 설치해줘야한다.
다운로드 링크: https://dev.mysql.com/downloads/connector/j/
해당 링크로 이동해 설치후 mysql-connector-java-버전.jar파일을
{kafka-connector디렉토리}/share/java/kafka에 복사한다.

이제 Connect의 REST API를 통해 Source Connector와 Sink Connector를 생성해보자.
Source Connector
아래 처럼 connect에 요청을 통해 Source Connector를 생성하자.
{
"name": "my-source-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/test",
"connection.user":"root",
"connection.password":"비밀번호",
"mode":"incrementing",
"incrementing.column.name" : "id",
"table.whitelist" : "users",
"topic.prefix" : "example_topic_",
"tasks.max" : "1",
}
}
cUrl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"포스트맨을 사용하면 다음과 같다.

각 속성의 의미는 다음과 같다.
- name : source connector 이름(JdbcSourceConnector를 사용)
- config.connector.class : 커넥터 종류(JdbcSourceConnector 사용)
- config.connection.url : jdbc이므로 DB의 정보 입력
- config.connection.user : DB 유저 정보
- config.connection.password : DB 패스워드
- config.mode : "테이블에 데이터가 추가됐을 때 데이터를 polling 하는 방식"(bulk, incrementing, timestamp, timestamp+incrementing)
- config.incrementing.column.name : incrementing mode일 때 자동 증가 column 이름
- config.table.whitelist : 데이터를 변경을 감지할 table 이름
- config.topic.prefix : kafka 토픽에 저장될 이름 형식 지정 위 같은경우 whitelist를 뒤에 붙여 example_topic_users에 데이터가 들어감
- tasks.max : 커넥터에 대한 작업자 수(본문 인용.. 자세한 설명을 찾지 못함)
실행 후 아래 요청을 통해 생성된 Connectors List를 확인할 수 있다.
cUrl -X GET -d @- http://localhost:8083/connectors
이제 test.users table에 데이터를 insert해보자.

그리고 kafka server 디렉토리에서 아래 명령어를 통해 topic 리스트를 확인해보면 example_topic_users 토픽이 생성된 것을 확인할 수 있다.(DB에 데이터를 삽입함으로써 Source Connector가 DB데이터를 topic에 push한 것)
$ ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Sink Connector
이제 Source Connector를 통해 topic에 넣은 데이터를 Sink하기 위해 Sink Connector를 생성해보자
Source Connector와 동일하게 아래처럼 API통해 생성한다.
{
"name": "my-pksink-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:mysql://localhost:3306/test",
"connection.user":"root",
"connection.password":"비밀번호",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"example_topic_users"
}
}
cUrl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"
sourceConnector와 겹치는 속성을 제외한 속성은 다음과 같은 뜻을 가진다
- auto.create : 데이터를 넣을 테이블이 누락되었을 경우 자동 테이블 생성 여부
- auto.evolve : 특정 데이터의 열이 누락된 경우 대상 테이블에 ALTER 구문을 날려 자동으로 테이블 구조를 바꾸는지 여부 (하지만 데이터 타입 변경, 컬럼 제거, 키본 키 제약 조건 추가등은 시도되지 않는다)
- delete.enabled : 삭제 모드 여부
더 자세한 속성은 해당 링크에서 확인할 수 있다.
https://docs.confluent.io/kafka-connect-jdbc/current/sink-connector/sink_config_options.html
생성후 users table에 데이터를 insert하면

example_topic_users table이 생성된 것을 볼 수 있고
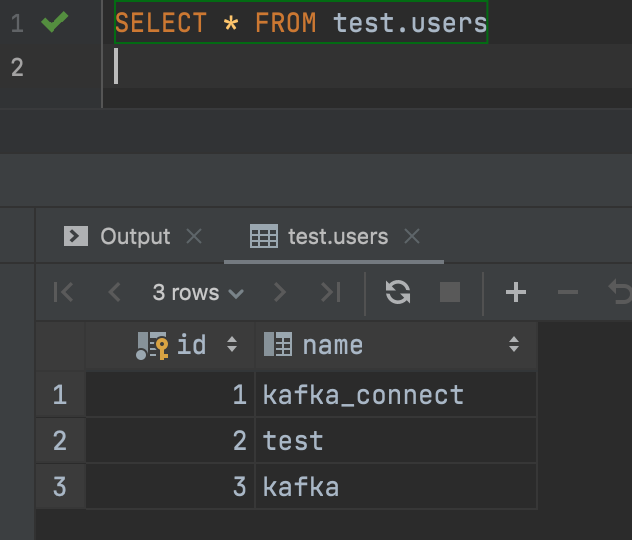

서로 테이블의 내용이 같은 것을 확인할 수 있다.
참고
https://debezium.io/documentation/reference/1.3/architecture.html
'스프링' 카테고리의 다른 글
| [스프링] 로깅 개념/설정 예제(feat. Logback) (0) | 2022.03.21 |
|---|---|
| [스프링] 멀티 모듈(Multi Module) 개념/예제 feat. Gradle (3) | 2021.12.19 |
| [Spring Cloud] Eureka 개념 및 예제 (0) | 2021.09.13 |
| [스프링] Validation 방법(Validator, Bean Validation) 설명/예제 (0) | 2021.08.07 |
| [JPA] 3. 엔티티 연관 관계 매핑 정리/예제 (7) | 2021.02.28 |


